
You can create automated triggers with AWS Lambda functions to launch an execution or pipeline when new data is pushed to a S3 bucket.
Prerequisites:
- Existing Valohai project
- AWS access and a S3 bucket
Generate a Valohai API Token
You'll need to generate a Valohai API key to authorize your requests with your Valohai projects.
- Go to https://app.valohai.com
- Click on the "Hi, <username>!" on the top-right corner
- Go to My Profile -> Authentication
- Click on Manage Tokens and scroll to the bottom of the page to generate a new token
Make a note of the token that pops up on the top of your page. It will be shown only once.
Create AWS Lambda function for S3
Create a Lambda function with a S3 trigger. The Lambda function will launch an execution or a pipeline when data is uploaded.
To create the trigger you will need:
- AWS account
- S3 Bucket
- Create a Lambda function
- Configure the function
The full guide on how to create the S3 trigger can be found here:
https://docs.aws.amazon.com/lambda/latest/dg/with-s3-example.html
After creating the S3 trigger you will need to configure the Prefix or Suffix for the S3 trigger.
Define a prefix
You can either define a folder (Prefix, eg. images/) and/or filetype (Suffix, eg. *.jpg). This will define which folder or filetype will launch the trigger.
Depending on your Valohai project settings, your execution outputs might be uploaded to the same S3 Bucket. In this case it's important to use a prefix to ensure that new files generated by Valohai (in data/) don't trigger a new execution. Otherwise you might end up in a loop of executions (S3 Trigger -> Run a Valohai execution -> Output files to S3 -> Trigger execution for new file)
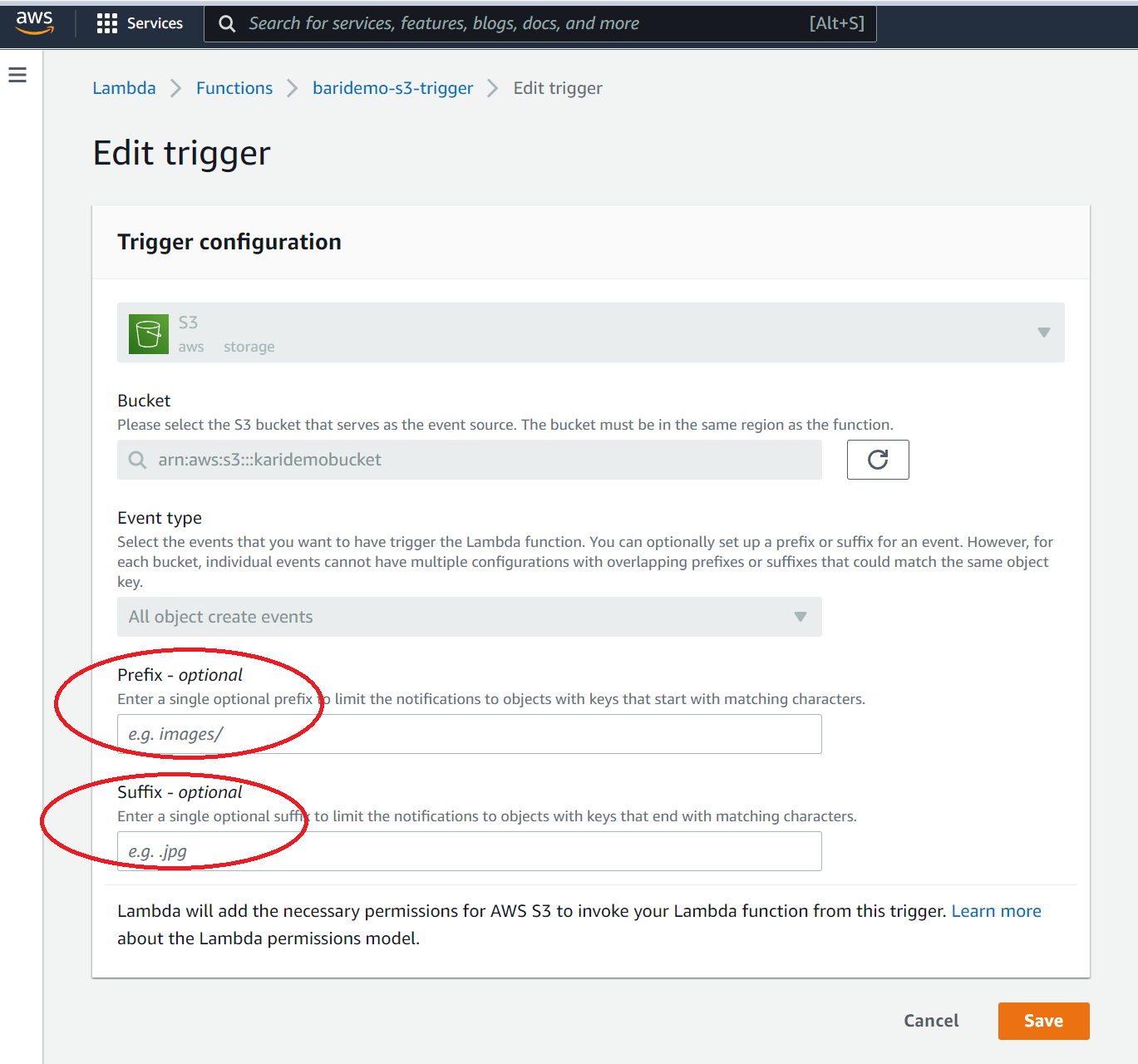
Configure your S3 trigger with Valohai information
Once you have created the S3 trigger you will have to add the API token and edit the function code with the necessary Valohai information.
API Token
In the sample below we have created a VH_TOKEN local environment variable.
Remember to follow your organization's security standards when handling the token.
To create a local environment variable: Open your S3 trigger and select Configuration - Environment Variables tab. Create an environment variable called VH_TOKEN and store the Valohai API token information here.
Valohai project information
You’ll need to know your project ID, commit, step and datum to continue. You can find your project’s ID, commit, step and datum if you create a new execution in your project and scroll to the bottom of the screen and click Show as API call.

Next you'll need to update your AWS Lambda S3 trigger with the necessary Valohai information.
The AWS trigger will launch when new files are uploaded to S3. When the Lambda function is called, it will include details about the file that was just added. We'll pass this file to a Valohai pipeline.
Below you can find an example JSON for launching an execution or a pipeline.
To update the code for the function open your Lambda S3 trigger and select code tab. You can either write your own JSON or copy-paste the below sample with your information.
Execution sample
import json
import urllib.parse
import boto3
import requests
import os
print('Loading function')
s3 = boto3.client('s3')
def lambda_handler(event, context):
auth_token = os.environ["VH_TOKEN"]
# The lambda event will contain a list of files (Records)
# We'll take the first file object and find the S3 bucket name
bucket = event['Records'][0]['s3']['
# Send the JSON payload to the right Valohai API
resp = requests.post('https://app.valohai.com/api/v0/executions/', headers=headers, json=new_execution_json)
resp.raise_for_status()
print(json.dumps(resp.json(), indent=4))
Pipeline sample
import json
import urllib.parse
import boto3
import requests
import os
print('Loading function')
s3 = boto3.client('s3')
def lambda_handler(event, context):
auth_token = os.environ["VH_TOKEN"]
# The lambda event will contain a list of files (Records)
# We'll take the first file object and find the S3 bucket name
bucket = event['Records'][0]['s3']['bucket']['name']
# Then we'll extract the path to the file inside the bucket
key = urllib.parse.unquote_plus(event['Records'][0]['s3']['object']['key'], encoding='utf-8')
# Generate a URL to the new file using the extracted data
# e.g. s3://mybucket/images/animals/horse.jpeg
url_to_new_file = f's3://{bucket}/{key}'
# Get the Valohai API token you created earlier.
# Here it has been stored in a local environment variable.
# Remember to follow your organization's security standards when handling the token.
auth_token = os.environ['VH_API_TOKEN']
headers = {'Authorization': 'Token %s' % auth_token}
new_pipeline_json = {
"edges": [
{
"source_node": "preprocess",
"source_key": "preprocessed_mnist.npz",
"source_type": "output",
"target_node": "train",
"target_type": "input",
"target_key": "dataset"
},
{
"source_node": "train",
"source_key": "model*",
"source_type": "output",
"target_node": "evaluate",
"target_type": "input",
"target_key": "model"
}
],
"nodes": [
{
"name": "preprocess",
"type": "execution",
"template": {
"commit": "master",
"step": "preprocess-dataset",
"inputs": {
"dataset": url_to_new_file
}
}
},
{
"name": "train",
"type": "execution",
"template": {
"commit": "master",
"step": "train-model",
"image": "tensorflow/tensorflow:2.6.0"
}
},
{
"name": "evaluate",
"type": "execution",
"template": {
"commit": "Git commit identifier",
"step": "Valohai step",
"image": "tensorflow/tensorflow:2.6.0"
}
}
],
"project": "your project ID here",
"tags": [],
"title": "Training Pipeline"
}
# Send the JSON payload to the right Valohai API
resp = requests.post('https://app.valohai.com/api/v0/pipelines/', headers=headers, json=new_pipeline_json)
resp.raise_for_status()
print(json.dumps(resp.json(), indent=4))
Comments
0 comments
Please sign in to leave a comment.